Introduction
This section provides a high-level overview of our PrizmDoc® AI features: Auto Summarization, Auto Tagging & Classification, and Document Q&A. We have included a data flow diagram, system requirements, licensing information, API reference documentation, and FAQs to help you get started.
Auto Summarization
PrizmDoc's Auto Summarization feature leverages AI to:
- Condense lengthy documents into concise summaries that capture key points.
- Generate summaries either automatically or on demand to suit your workflow.
- Easily access and manage summaries within your platform using our intuitive GET and POST APIs.
Auto Tagging & Classification
PrizmDoc's Auto Tagging & Classification feature utilizes AI to:
- Provide an automated way for you to identify potential tags and category classifications of documents.
- Programmatically perform tagging/classification or manually apply tags and classifications.
- Perform classification utilizing a pre-existing set of classifications.
- Provide an option to allow AI to suggest new tags and classifications.
- Use APIs to GET and POST tags and classifications with your platform.
Document Q&A
PrizmDoc's Document Q&A feature uses AI to:
- Process a query from the end user to find answers within the document, then return those answers to the user via the PrizmDoc UI.
The PrizmDoc UI includes the ability to:
- Enter and execute a query
- View the query results
- Modify the query and execute the updated query
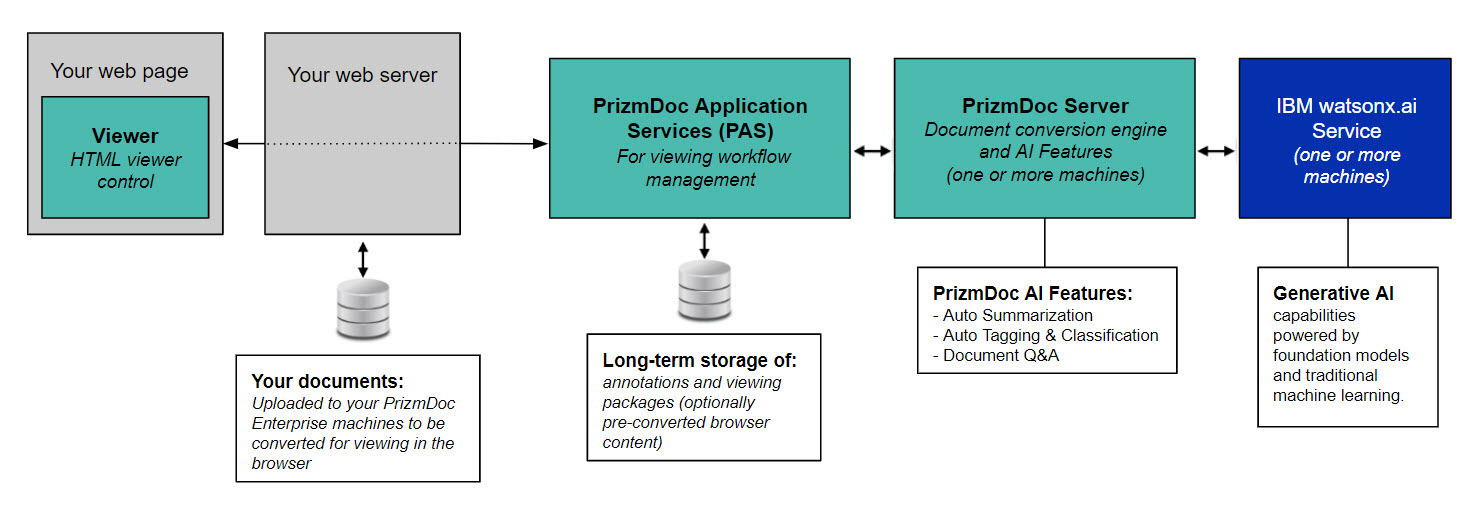
PrizmDoc AI Feature Data Flow Diagram
PrizmDoc Server includes the AI features within the document conversion engine:
Requirements for Installation of AI Features
This section covers the basic hardware requirements. Note that requirements can change based on your use case and the Foundation Models you need (refer to the Foundation Models section below).
Hardware Required for Self-Hosting
There are two options for self-hosting the PrizmDoc version of IBM® watsonx.ai™ v5. You will want to start with the "Lightweight" install initially, but as our PrizmDoc AI functionality and capabilities expand, you may opt for the "Full" install as it will provide you with extended management tools (refer to the Feature Comparison chart for more details).
1 - Lightweight Install:
- An OpenShift cluster with 24 CPU cores
- 150GB RAM
- Disk requirements: 600GB
- Implemented Foundation Models require:
- 4 CPU cores
- 2 GPUs - currently supported:
- NVIDIA A100 GPUs with 80GB RAM
- NVIDIA H100 GPUs with 80GB RAM
- NVIDIA L40S GPUs with 48GB RAM
- 256GB RAM
2 - Full Install:
- An OpenShift cluster with 64 CPU cores
- 300GB RAM
- Disk requirements: 600GB
- Foundation Models (initial deployment supports English with 2 of the 27 available models) require:
- 4 CPU cores
- 2 GPUs - currently supported:
- NVIDIA A100 GPUs with 80GB RAM
- NVIDIA H100 GPUs with 80GB RAM
- NVIDIA L40S GPUs with 48GB RAM
- 256GB RAM
Hosting Options
There are 2 options for hosting:
- IBM WatsonX cloud
- Servers on-prem/private cloud (AWS is a hosting option)
NOTE: Currently the AI Features are not available in PrizmDoc Cloud.
Licensing
At this time, we only offer a paid, self-hosted option. We do offer a paid "Developer All Access" license that gives you full access to all new AI functionality in PrizmDoc. Due to the costs of running AI, we are not able to offer this as a "free" trial at this time. We are working to provide a cloud-hosted "trial" option that we hope we can offer at much lower cost for trial purposes.
Foundation Models
Overview
IBM watsonx.ai has Foundation Language Models that are trained for a variety of general and specific functions and include English, Arabic, French, German, Hindi, Italian, Japanese, Korean, Portuguese, Spanish, Thai and some Foundation Models are listed as "Multilingual" or "dozens of other languages".
Included in Our Product
Our initial deployment uses two of these Foundation Models and is deployed with support for English. If you have a specific language requirement for your use case, please contact us to discuss which Foundation Model can be switched out to work best for you.
Training AI Models
If you choose the self-hosted option, you can train the AI models to improve results. If you choose the cloud-hosted option, you cannot train the models.
FAQs
- Do the AI features have samples in the public github repo? Not currently, but as our PrizmDoc AI functionality and capabilities expand, they may be added.
- What is the number of characters of input processed vs. hardware consumed vs. time taken? This varies widely based on the selected Foundation Model. It is best to get a clear understanding of your use case, for example, what features will you use and what languages do you need supported. Please contact us so we can determine the best Foundation Model to meet your requirements and provide the requested information.
- When users tag documents, where are those tags stored? Tags are delivered via JSON for the customer to ingest into their application. The customer can also populate the tags shown in the UI by sending that JSON data from their system. PrizmDoc does not store the tags.
- Can we report on tags and/or collect that data? PrizmDoc does not have any reporting capabilities. This would be handled within your application.
- Will tagging be a server-based process as well, or limited to the UI? Tagging is done by PrizmDoc Server. The calls to have a document tagged are done via an API call. Our UI is just a manual way to execute that API call.
- Will the tagging categories be customizable? Currently, only Classifications are customizable to your specific instance. This is controlled in a configuration file.
API Reference Documentation
- Auto Summarization - Use our PAS Document Summarizers REST API (if using our Viewer) or the PrizmDoc Server Document Summarizers REST API (for direct calls to the server without a viewer) to perform document summarization which provides concise summaries of lengthy documents.
- Auto Tagging & Classification - Use our PAS Document Taggers and PAS Document Classifiers REST APIs (if using our Viewer) or the PrizmDoc Server Document Taggers and PrizmDoc Server Document Classifiers REST APIs (for direct calls to the server without a viewer) to perform document tagging and classification which intelligently tags and categorizes content.
- Document Q&A - Use our PAS Document Queriers REST API (if using our Viewer) or the PrizmDoc Server Document Queriers REST API (for direct calls to the server without a viewer) to perform document Q&A which retrieves pertinent information within documents.