PrizmDoc v12.4 - Updated
Document Workflow
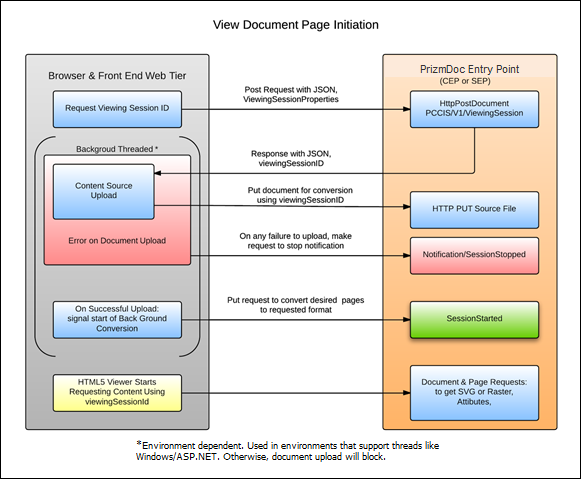
The PrizmDoc Server architecture is based on a two-tier web solution where the SEP, or CEP, is the backend tier and the front end tier is a light-weight-pass-through tier keeping the customer’s web application simpler to implement the PrizmDoc Server. There is a slight cost to this approach in that source documents need to be uploaded from the front end web tier to the PrizmDoc Server tier. The recommendation is to embed code into the web page to initiate the upload sequence of the document and start the PrizmDoc Server preparing the document for viewing. Another caveat to consider is that the document identification needs to be supplied by PrizmDoc Server so that it can better manage that resource once it is uploaded.
The recommended process for document viewing (as shown in the diagram below):
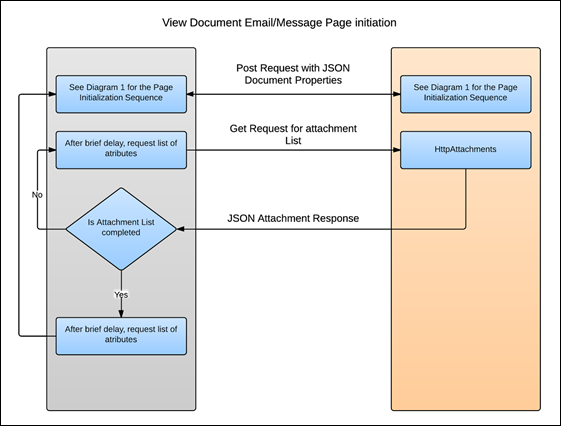
The viewing of email or message files is a more complicated process where the body of those types must be dissected into individual pieces for any attachments. Each attachment has its own document ID (now called Viewing Session Id) which must be handled separately. The web page must determine if a document query string parameter or a session identifier query string, viewingSessionId, is being used as the query string. In general, the viewingSessionId is the identification element for correspondence with PrizmDoc Server.
The general concept is illustrated below: